Crafting Backup as a Service solution using Akka Streams
Using Akka Streams to backup data from MongoDB to Amazon S3.
July 31, 2017 ·Part 1 Part 2

Imagine you’re developing a database as a service solution like Compose or mLab. You’re hosting a horde of database instances/containers used by your customers. One of the critical features of your solution is performing backups since no one is willing to lose data. You are already doing backups in the form of e.g. volume snapshots, just in case of a disaster in your infrastructure (and you obviously test your automated recovery procedure frequently to prove it’s up to date ;)).
What if you wanted to let your customers do automatic backups of their data (or some selected part of it), so they could restore it on demand?
In this post, we’ll craft a production-ready backup as a service solution. We’ll see how to use Akka Streams in connection with Alpakka, which is a powerful open-source library of connectors for Akka Streams, to stream the whole MongoDB collection to Amazon S3. What’s more, at the end, we’ll enhance our stream with compression and encryption as we obviously want to guarantee maximum safety with a minimal storage cost. And, of course, we’ll do all of this in Scala! Sounds cool? Read on!
The Stream
The diagram below is a high-level overview of a stream we will implement in a minute.
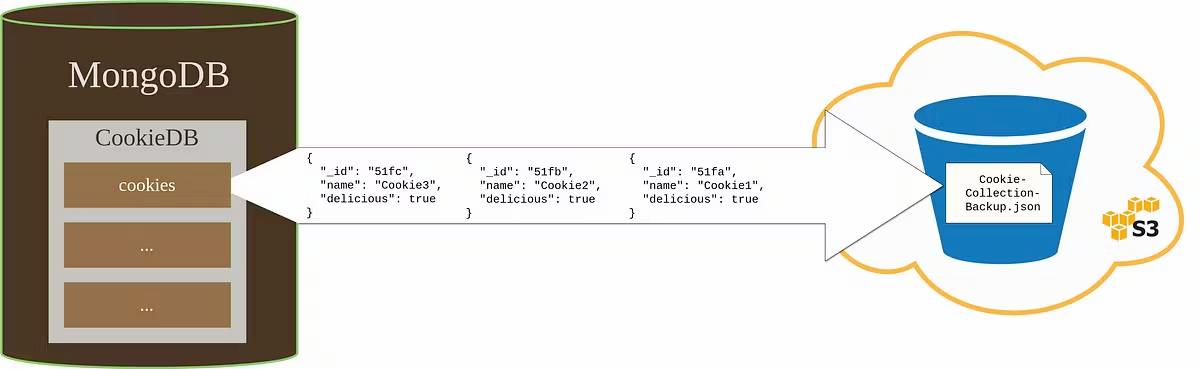
The stream will be constructed as follows: it’ll start from a MongoDB collection, in our case cookies. Then, there will be a logic that converts BSONs to JSONs, which will eventually end up being streamed to a file in Amazon S3 bucket. Now it’s time to see some code!
The Code
The snippet below presents the whole solution. It streams a MongoDB collection to a file named CookieCollectionBackup.json into the bucket bucketWithCookies on Amazon S3.
The code below uses three dependencies: Akka Streams, Alpakka S3 connector and MongoDB Reactive Streams driver.
I added a surplus amount of type annotations in order to help you better understand it just by looking at types.
Source.fromPublisher(collection.find(): Publisher[org.bson.Document])
.map((doc: org.bson.Document) ⇒ doc.toJson())
.map((json: String) ⇒ ByteString(json))
.runWith(s3Sink)
val s3Sink: Sink[ByteString, Future[MultipartUploadResult]] =
s3Client.multipartUpload(
bucket = "bucketWithCookies",
key = "CookieCollectionBackup.json"
)
- In the 1. line, we start our stream with a Source of BSON documents. We do it by passing
collection.find(), which returns aPublisherfrom Reactive Streams with BSON documents, toSource.fromPublisherhelper. It accepts Reactive Streams publishers and creates Akka Streams source out of them. - In the 2. line we transform each BSON document received from MongoDB to JSON* form, which is a String. In order to achieve this, we use
toJsonmethod on BSON document. - In the 3. line, we transform our String with JSON inside to ByteString. That’s because it’s required by the Sink, in our case
s3Sink. - In the 4. line, we want our stream to run with
s3Sink, which is defined in line 6. It writes to S3 usings3Clientfrom Alpakka.
In fact, it’s an Extended JSON*. Since BSON has more types than plain JSON, MongoDB introduced an Extended JSON format.* Read more about it* *in the MongoDB manual*.*
I highly encourage you to run the stream yourself. You can find the full runnable code in the Github repo: bszwej/mongodb-s3-stream-example.
The multipartUpload sink
Let’s take a closer look at our sink (s3client.multipartUpload), which signature is defined as follows in Alpakka:
def multipartUpload(
bucket: String,
key: String,
contentType: ContentType = ContentTypes.`application/octet-stream`,
metaHeaders: MetaHeaders = MetaHeaders(Map()),
cannedAcl: CannedAcl = CannedAcl.Private,
chunkSize: Int = MinChunkSize,
chunkingParallelism: Int = 4
): Sink[ByteString, Future[MultipartUploadResult]]
Apart from specifying the bucket and file name, it allows us to:
- Specify a chunk size, which is 5mb by default.
- Specify parallelism of sending chunks, which is 4 by default.
- Specify a content type and metadata.
If you’re curious about how parallel upload of chunks is realized, then take a look at S3Stream#createRequests.
Adding compression
When building a solution like backup, it’s highly likely you want to apply compression to the backups in order to optimize the cost of storage. In fact, Akka Streams has a few built-in flows, that allow compressing streams of ByteStrings. They can be found here: akka.stream.scaladsl.Compression. After adding a gzip compression to our stream, the code looks like the following:
Source.fromPublisher(collection.find(): Publisher[org.bson.Document])
.map((doc: org.bson.Document) ⇒ doc.toJson())
.map((json: String) ⇒ ByteString(json))
.via(Compression.gzip: Flow[ByteString, ByteString, NotUsed])
.runWith(s3Sink)
val s3Sink: Sink[ByteString, Future[MultipartUploadResult]] =
s3Client.multipartUpload(
bucket = "bucketWithCookies",
key = "CookieCollectionBackup.json"
)
As you might have noticed, in line 4. we make our stream go through a flow, which is a Compression.gzip. It accepts and outputs ByteStrings performing the gzip compression.
Adding encryption
We can distinguish two kinds of encryption when crafting a backup solution:
- In transit encryption. It’s applied when data is being sent/downloaded to/from S3. As far as S3 is concerned, data in transit can be secured by using either SSL or Amazon’s Client-Side encryption of which the latter is, sadly, not supported by Alpakka S3 connector. In this case, you can always rely on SSL, which is always enabled by default.
- At rest encryption. It’s applied when data is persisted on disk in one of Amazon’s data centers. It’s decrypted when you download the data. From the client’s perspective, there’s really no difference because it’s encrypted/decrypted internally by S3. It can be realized by Amazon’s Server-Side Encryption and can be used with Alpakka. You can easily do it just by specifying a header, namely
x-amz-server-side-encryption. In the snippet below we added such encryption.
Source.fromPublisher(collection.find(): Publisher[org.bson.Document])
.map((doc: org.bson.Document) ⇒ doc.toJson())
.map((json: String) ⇒ ByteString(json))
.via(Compression.gzip: Flow[ByteString, ByteString, NotUsed])
.runWith(s3Sink)
val s3Sink: Sink[ByteString, Future[MultipartUploadResult]] =
s3Client.multipartUploadWithHeaders(
bucket = "mycookiesbucket12345",
key = "CookieCollectionBackup.json",
s3Headers = Some(S3Headers(ServerSideEncryption.AES256))
)
In the line 8. we used s3Client.multipartUploadWithHeaders sink and specified a ServerSideEncryption header. Under the hood, it just adds a header: x-amz-server-side-encryption: AES256. After running the stream, the file is encrypted which can be seen in the properties on S3:

If the above solution is enough for your project, then go with it. It’s the simplest one. But what if you wanted to encrypt the data in the stream before sending it to AWS? The data would be then encoded in transit as well as at rest. This topic is huge and is a good material for a separate blog post. In short, you can use this snippet made by @TimothyKlim.
Summary
So… that would be it! You could have noticed how easy it is to do integrations between systems using Akka Streams and Alpakka. One could argue, that a similar effect of streaming a large amount of data could be realized solely by actors. It’d be much more difficult since things like buffering, throttling or backpressure, which actors don’t provide by default, would come with an increased code as well as test complexity (btw. Collin Breck wrote an outstanding article about it).
To sum up, Akka Streams seems to perfectly fit for the problem we were trying to solve: doing on-demand backups for our customers. I’d also like to mention, that the solution shown in this post is working like a charm on production for months in one of the projects in my organization. Crafted with scalability and reliability in mind, it turned out to be very stable over the period of the last few months.
In the subsequent post, we’ll implement the restore part of our backup solution. Thanks for reading! Stay tuned and happy hAkking :)!
Resources
- https://github.com/bszwej/mongodb-s3-stream-example
- http://developer.lightbend.com/docs/alpakka/current/s3.html
- https://docs.mongodb.com/manual/reference/mongodb-extended-json/
- http://blog.colinbreck.com/akka-streams-a-motivating-example/
- http://api.mongodb.com/java/current/org/bson/Document.html#toJson--
- http://doc.akka.io/api/akka/current/akka/util/ByteString.html
- http://doc.akka.io/api/akka/current/akka/stream/scaladsl/Compression$.html
- https://docs.aws.amazon.com/AmazonS3/latest/dev/UsingEncryption.html